Improving LLM Code Generation with Intentional Mistakes
Sean McHale
Team: 2 members
Status: CompleteTags:
Can inserted errors improve the performance of LLMs? This project investigates the impact of inserting errors in proposed coding solutions and if the performance of LLMs can be improved by doing so.
Introduction
Large Language Models (LLMs), such as GPT-3.5 and GPT-4, have recently shown significant progress in their code generation abilities. These models can take in natural language instructions and generate code that meets the user's instructions. However, the code generated by these models is often incorrect, due to both logical and syntactical errors. This project introduces a novel prompt engineering technique, use mistake, which first asks the LLM to construct an erroneous response to the coding problem. Then, that code is passed along with the original prompt to construct the final response. To benchmark the prompting techniques, two code evaluation datasets were used: HumanEval and PythonSaga. The use mistake technique achieved better performance than the standard coding attempt benchmark on the HumanEval dataset with 10 passes. An exploratory analysis was also conducted on how different prompting methods fail specific coding problems.
Data
Two different datasets were used to evaluate the effects of various prompting techniques on LLM code generation. The first dataset was HumanEval, a code evaluation dataset that contains 164 hand-crafted Python basic programming problems, designed to ensure that LLMs were not directly trained on these problems. Each of these problems contains a prompt with the method header and example inputs/outputs, along with an example solution and unit tests for the generated code. A significant benefit of using HumanEval is that the code automating the testing of LLM-generated outputs is publicly available. Since its creation in 2021, HumanEval has been widely used to evaluate and test code generation models. The second dataset, PythonSaga, was recently released in 2024 and contains 185 Python programming problems. These problems were curated from popular coding platforms Geek-for-Geeks and LeetCode. The authors reformulated the problems taken from these coding platforms to maintain the same underlying functionality while transforming the prompting text to make it harder for LLMs to pattern-match the prompt, forcing them to recognize the underlying concepts in different contexts.
Methodology
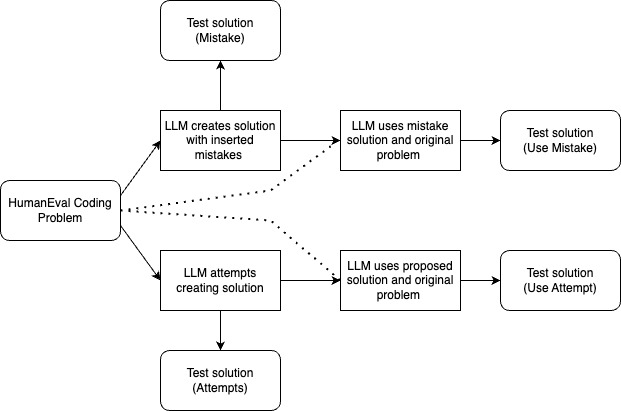
This section describes the four different prompting methods tested with LLM code generation.
Attempt
The first prompting method was passing the raw prompt of the coding task from the dataset in use. The purpose of this attempt is to act as a baseline to compare the performance of our other prompting methods to. The code generated by this raw attempt is also used in our second technique.
Use Attempt
The next prompting method is the use attempt method which provides the LLM with an example LLM generated solution when asking it to solve the same problem. The direct prompt used was:
This is an attempt to the function: \n {problem} \n {attempt} \n If the solution is correct please output the existing function code. If the solution is incorrect fix and output the function code. \n {problem}
{problem} contains the raw prompt and {attempt} contains the output of a previous raw attempt. The idea of this strategy was to see if providing the LLM with an example solution could improve its accuracy/identification of errors in the previous attempt's strategy.
Mistake
Our next prompting method was the mistake method. This is where we asked the LLM to incorrectly answer the coding problem that we provided it. The prompt we used was:
Complete this task with mistakes. Only return your addition to the existing code. Do not repeat the function header. \n {problem}.
The purpose of this method is to be used in the use mistake prompting method, which requires an example erroneous LLM output.
Use Mistake
The final prompting method is our novel use mistake method. In this method, we passed an erroneous example LLM generated solution along with the problem. The prompt used was:
This is an attempt to the function: \n {problem} \n {attempt} \n If the solution is correct please output the existing function code. If the solution is incorrect fix and output the function code. \n {problem}.
The intention behind this method is to prompt the LLM to be more cognizant and mindful of errors, such as the ones in the wrong attempt that they are passed. We hoped that this would then correlate to reduced number of errors and better generated solutions.
Evaluation
We used both HumanEval and PythonSaga to evaluate our code prompting methods. The evaluation method used in the HumanEval paper, pass @ k, has become the standard for measuring LLM code generation accuracy. This strategy involves passing the same prompt to the LLM k times. If any of the k generations pass all of the unit tests, then this problem is given a score of "1" for solving the problem. Otherwise, it is given a score of "0". Calculating the mean of these scores across the code evaluation dataset that is being used then yields the final score. We calculated pass @ 1, 5, and 10 for all of the different prompting methods. Furthermore, we propose a novel combined metric that shows the overall combined power of the attempt and use mistake methods. Simply, this metric checks if either one of these prompting methods yielded a correct output.
Implementation Details
For our LLM, we use OpenAI's GPT-3.5 Turbo with a temperature of 0.8, as that is the standard temperature used with HumanEval. We chose GPT-3.5 Turbo due to significantly lower associated costs for repeated LLM passes with different prompts and methods and GPT-4 Turbo already having the best performance on the HumanEval dataset. We hoped to increase performance with a worse but much cheaper model to show the benefits of our prompting technique. After 10 passes for each problem, we ran the generated code in a Docker container to benchmark using the unit tests and store the results. We also stored the individual LLM generated outputs and benchmark results for more detailed output analysis. Check out our code here.
Results
Figure 1
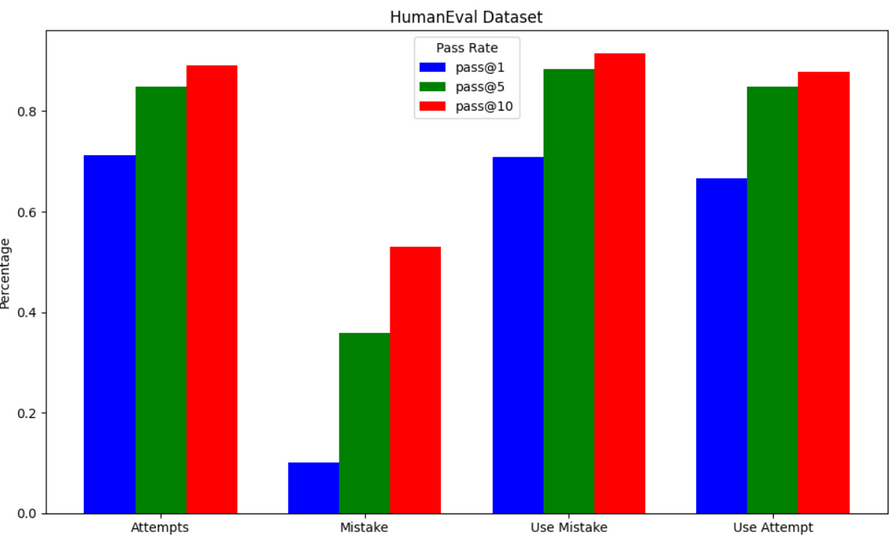
Figure 2
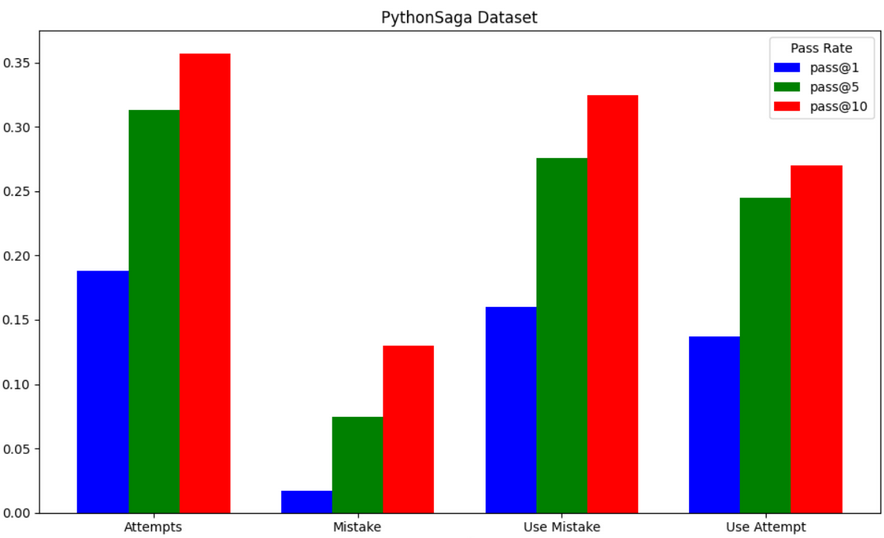
Figure 3
Looking at Figure 1 and Figure 2, we can clearly see that the LLM performs significantly better on HumanEval than PythonSaga. This makes sense as PythonSaga is much newer, and thus GPT-3.5 has had less exposure to its problems. Furthermore, as the authors of PythonSaga transformed the coding prompts to be harder for LLMs to identify the underlying question/function of the problem, it makes sense that all prompting methods perform significantly worse on it. For HumanEval, the use mistake prompting method had the best performance, while for PythonSaga, the attempt method performed the best. Given that PythonSaga's involved preprocessing result in significantly poorer overall results, and HumanEval is the more tested dataset, we conducted most of our analysis with HumanEval.
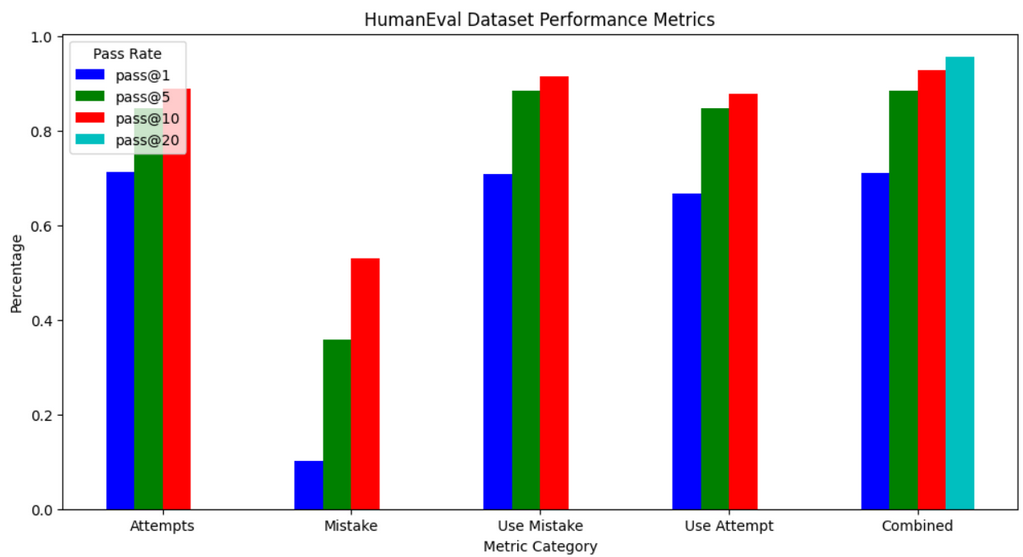
Interestingly, the attempt and use mistake methods don't fail the same problems. We can combine their results to create the metric Combined for HumanEval seen in Figure 3.
Code Example
One problem which use mistake succeeded while attempt did not was:
"How many 7s are in numbers that are divisible by 11 or 13 between 1 to n, where n is an input passed in."
The attempt method fails to understand that numbers can have multiple 7s, and that these need to be counted individually. An example generation is:
count = 0
for i in range(1, n):
if i % 11 == 0 or i % 13 == 0:
if '7' in str(i):
count += 1
return count
use mistake successfully answered this question with the generation:
count = 0
for i in range(1, n):
if i % 11 == 0 or i % 13 == 0:
for digit in str(i):
if digit == '7':
count += 1
return count
Interestingly, the mistake generated code for this solution is not close to the correct solution:
if i % 7 == 0:
count += 1
continue
return count
Although not always reliable, mistake-generated outputs can influence LLMs to solve problems they previously could not.
Conclusion
This project proposes a new prompting technique for LLMs that resulted in improved performance with HumanEval pass @ 10. More research will need to be done to explore repeatability and reliability of this technique.
Extra
| Prompting Technique | HumanEval Pass@1 | HumanEval Pass@5 | HumanEval Pass@10 | PythonSaga Pass@1 | PythonSaga Pass@5 | PythonSaga Pass@10 |
|---|---|---|---|---|---|---|
| Attempt | 71.28 | 84.85 | 89.02 | 18.81 | 31.32 | 35.68 |
| Mistake | 10.06 | 35.80 | 53.05 | 1.68 | 7.46 | 12.97 |
| Use Mistake | 70.79 | 88.41 | 91.46 | 16.00 | 27.57 | 32.43 |
| Use Attempt | 66.65 | 84.88 | 87.80 | 13.68 | 24.49 | 27.03 |